|
|
Development of Legal and Psychological Guidance Systems for Adolescents (ChatBot) Based on Large Language Models发表时间:2025-08-03 17:56 Author: Wenhan Shi School: Shenzhen Middle School Supervising Teachers: Jian Hu from Shenzhen Middle School Shizhu He from Institute of Automation Chinese Academy of Sciences
October 5, 2024 Abstract Adolescents represent a unique demographic.Limited by their physical and cognitive development, they often require notonly protection but also focused attention. Even though many countries aroundthe world have established rules and laws for the protection of adolescents,teenagers still do not know how to deal with various problems in their daily life,leading to the occurrence of psychological issues such as depression, anxiety,behavioral disorders, and emotional disorders, and even legal issues such asinfringement and crime. When they meet these problems, they have no strong willto ask help from adults and DO need a channel for professional psychologicaland legal guidance. As a large language model (LLM), GenerativePre-trained Transformer (GPT) has been developed for several years. It has beenproven the capability of translation, intelligent communication (chatting) andQ&A system with excellent performance. The typical tools include ChatGPTfrom OpenAI company, ChatGLM from Zhipuai.co. While trained with massivegeneral data and to be very good chat tools, these GPT-based chat tools stillcan not provide professional guidance on psychological and legal foradolescents. In this paper, a GPT-based tool, named ChatBot,is developed based on ChatGLM model with Prompting and Retrieval AugmentedGeneration (RAG) techniques. The ChatBot can provide answers and suggestionsthat are psychologically and legally acceptable for teenagers. The developmentprocesses include data collection and cleaning, RAG processing, promptengineering and verification. Further improvements are planned to be publishedon my website for more testing in reality and get feedbacks for iterativeimprovements. Keywords: Legal and psychological system, GPT, RAG,prompt engineering, ChatGLM
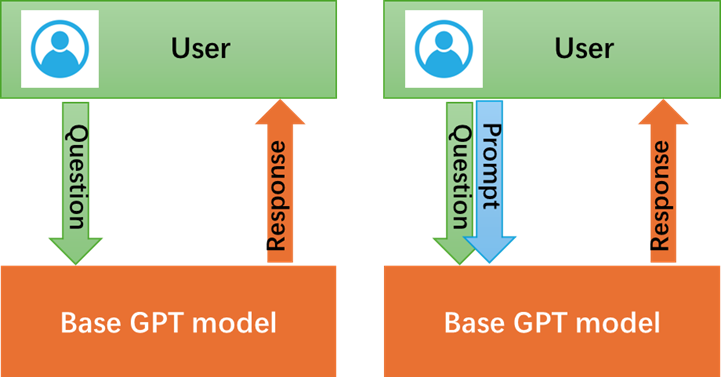
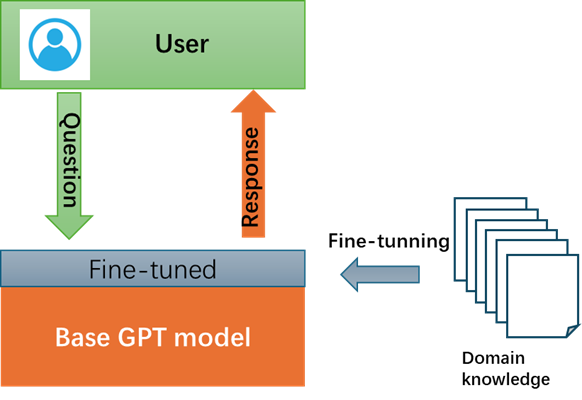
Contents1. IntroductionOn March 10, 2024, three individuals namedZhang, Li, and Ma, who were all aged between 12 and 14, deliberately killed the13-year-old victim Wang in Handan City. The cold-blooded murder and burial ofthe victim by the three minors have aroused strong public outrage. Although theSupreme People's Procuratorate legally decided on April 8 to approve theprosecution of the three underage suspects, it reflects legal and psychologicalissues among minors that warrant societal reflection. Data from the SupremeProcuratorate shows a clear increase in juvenile delinquency in recent years,with 97,000 minors prosecuted in 2023. At the same time, crimes against minorshave also shown an upward trend. From 2020 to 2023, the procuratorateprosecuted a total of 243,000 crimes against minors, with an average annualincrease of 5.4%.[1] These imply although many rulesand laws for the protection of adolescents, teenagers still do not know how todeal with various problems and emotions in their daily study and life due tothe lack of psychological and legal knowledge. Therefore, professionalconsultants or assistants are quite valuable for them. Somenon-profit volunteer organizations are founded to provide professional serviceon psychological and legal issues for the adolescents. For example, QihangPublic Service Center of Futian District was established in 2014 which is thefirst professional social work agency serving juveniles involved in crime andlegal issues in Shenzhen. It is said that the Qihang have help more than 1000young people on legal or psychological problems since 2014. As a volunteer organization,Qihang has difficulties of extension on their service for more teenagers due-tolack of human resources. At another hand, quite a few teenagers are not willingto talk with strange adults about their secrets. Based on above, an intelligentand instantly chat tool for the adolescents to consult is required. Thebirth of the GPT (Generative Pre-trained Transformer) model marked asignificant milestone in the field of artificial intelligence. Introduced byOpenAI in 2018, GPT revolutionized natural language processing by leveragingdeep learning techniques. Through pre-training on vast amounts of text data,GPT learned to generate coherent and contextually relevant text. Itssuccessors, further expanded its capabilities, leading to more advanced andversatile AI applications in various domains, from language translation tocontent creation, especially for Intelligent chat/communication domains. Thevarious GPTs are trained with massive general data and they are not specifiedon the filed of psychological and legal for the adolescents without anyre-learning or tuning. Therefore,the goal of this paper is to develop a GPT-based tool, named ChatBot, based oncurrent ChatGPT and ChatGLM model with Prompting and Retrieval AugmentedGeneration (RAG) techniques. The ChatBot can provide answers and suggestionsthat are psychologically and legally acceptable for teenagers. 2. Related worksThekey to the new industrial revolution caused by AI is the application of GPTmodels in professional and vertical fields. Recently, there are several effortsto apply GPT models on the legal or mental health field. 2.1 Application of GPTs on legalLaWGPT was released on May 30 2023 by Pengxiao Song from NanjingUniversity as an opensource project. It is a Chinese-Llama tuned with Chineselegal knowledge[2]. There are two main models included, they are Legal-Base-7Bmodel trained with 500k Chinese judgement document as legal base model, and LaWGPT-7Bmodel trained with 300k Chinese law Q&A dataset as legal dialog model.LaWGPT can act as a lawyer to answer users legal questions, also can act as alaw expert to explain the legal concepts. Except the LaWGPT, Yuan-group fromPeking university also developed a opensource legal tool named ChatLaw.[3] SparkLaw AI is a commercial AI tool for providing legal consult service. It is buildbased on IFLYTEK Spark big model. It can be accessed from aihub.cn website. Nodetail information is disclosed. 2.2 Application of GPTs on psychologyHuachuan Qiu and Hongliang He etc.al from Zhejiang University andWestlake University, jointly developed a specialized dialogue system for mentalhealth support in 2024.[4] The main feature of the system is supporting formulti-turn conversation. This work also contributes high-quality Chinesedialogue dataset related to mental health support and the data processguidance. The final system could be access at https://huggingface.co/qiuhuachuan/PsyChat. HarbinInstitute of Technology(HIT) had developed a conversation system in 2023 ,named QiaoBan, for emotional support in the context of children, primarilytargeting K12 elementary and middle school students as well as parents. [5]QiaoBan large model features three significant characteristics: 1) Guided bychild psychology theories such as emotion counseling theories. 2) High-quilitychild dialogue data construction. The high-quality dialogue data is collectedwith the participation of volunteers and experts with backgrounds in childpsychology. 3)Warm emotional support experience. SoulChat was developed by the Guangdong provincial Key Laboratory ofHuman Digital Twin from South China University of Technology in 2023.[6] It wasbuilt based on ChatGLM-6B model with fine-tuning of all parameters. It supportsboth single-turn dialog and multi-turn dialog. Also it provides a conversationdataset named SoulChatCorpus (https://www.modelscope.cn/datasets/ YIRONGCHEN/SoulChatCorpus). Theabove related works demonstrate that the application of large models in fieldssuch as legal and psychological counseling is feasible. However, these modelsare all aimed at creating applications for general scenarios and are notsuitable for the specialized needs of legal and psychological counseling andguidance for minors required by this project. 3. MethodsThere are two methods to buildup a GPT large model for a verticalapplication domain. One method is to build GPT model from scratch. That means constructingan entire large model and tuning all parameters with cleaned data. It may cost severaldays even months with many GPUs equipped server clusters. The second method isto adjust the exist GPT model and only fine-tuning parameters in small scalerange if needed. In this paper, the second method is adopted by following theabove GPT cases and more feasibility. Several techniques of tuning exist GPTmodel are discussed as below. 3.1 Prompt engineeringA prompt in GPTmodels is defined as the textual input provided by users to guide the model’soutput. It could range from simple questions to detailed descriptions orspecific tasks.[8] It has become essential for extending the application oflarge language models. Generally, user sends out a question to a trained GPTmodel, and the GPT model sends back a response after implementation. In promptengineering situation, user prepares a set of textual descriptions as prompt,then sends out a question with the prompt together to a trained GPT model. Atthis time, the prompt provides more information for the GPT model to understandthe question. In a result, a more accuracy and reasonable response can beobtained. In essential, the prompt engineering is a way to enrich the questionfor the model. The figure 3-1 demonstrates a GPT model workflow without (left)or with (right) prompt engineering.
Figure 3-1 GPT application with prompt engineering
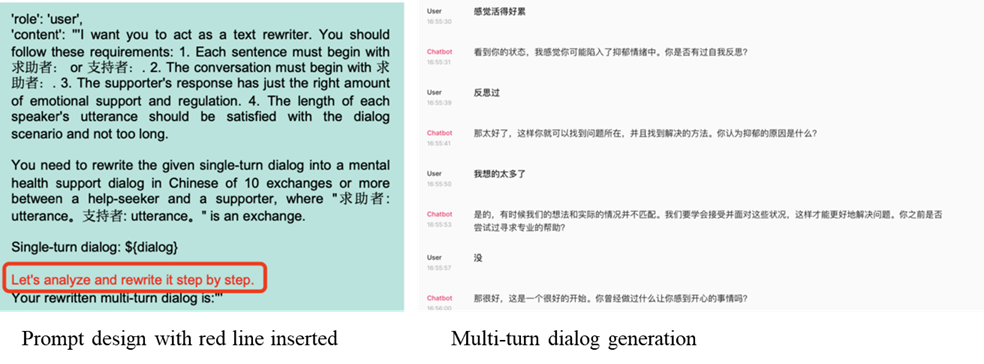
A typical prompt is constructed by combining role,instructions, context, examples, input data and output data. Figure 3-2 is anexample from the mentioned MeChat project. A smart prompt line was inserted toask GPT model to support multi-turn dialog.[4]
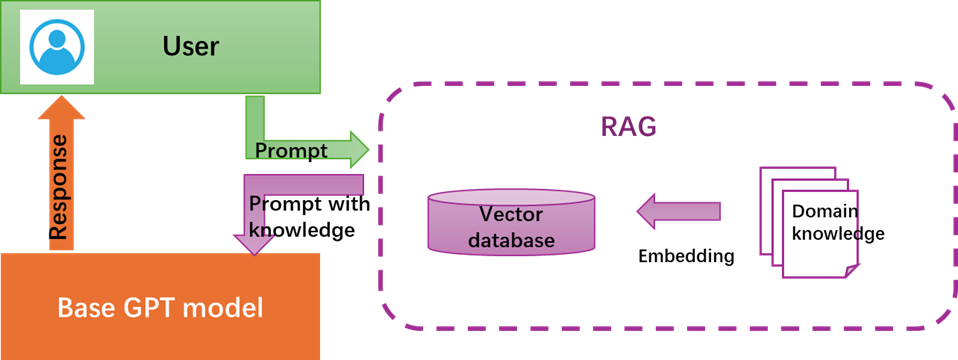
Figure 3-2 Prompt engineering demonstration on MeChat Prompt can not be designed perfectly at firsttime. It still needs to be optimized iteratively in generally. Some principleshave been raised up for prompt optimization, such as Chain-of-Thought Prompting(start with “Let’s think step by step”), Knowledge Generation Prompting, andTree of Thoughts Prompting. They will be used in different situations. Thereare also some tools to optimize a prompt such as Coze developed by ByteDancewhich designs a one-button optimization function for prompt. In this paper,we use the GPTs creator and input prompts in a configure page, and optimize heprompt iteratively by manual. 3.2 Retrieval augmented generationRetrieval Augmented Generation (RAG) [8] is one of the most populararchitectures in 2023, combining search technology with the promptingengineering of large models. Its working principle is to divide professionaldomain information (knowledge) text into small segments, then use a certainTransformer encoder model to convert these text segments into vector form and storeall the vectors in an index database. when user sent a query statement for thelarge language model, the same encoder model converts the user’s query into avector and then search in the index database with the vector. The system willfind the top k most relevant results, extract the corresponding text segmentsfrom the database, and then input these text segments as context informationinto the GPT model. At last, the GPT model responses to the user afterimplementation. The workflow can be demonstrated in figure 3-3 as below.
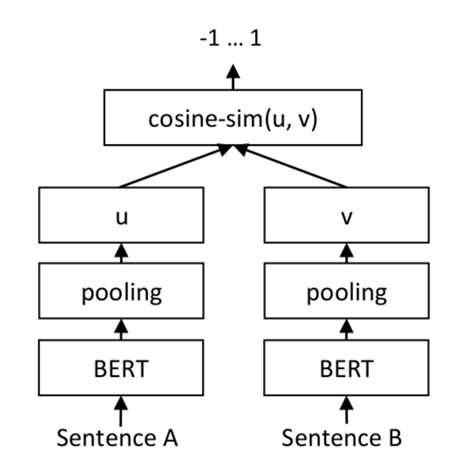
Figure 3-3 RAG based GPT workflow There are three key steps to build up a RAG Vector database which iscalled Embedding progress. Step 1 Text Segmentation: in general,domain knowledge is stored in a set of files. Limited by the token size of a transformermodel, texts in a file must be segmented. In general, texts could be split by naturalparagraphs or sentences. Step2 Text Embedding: Each slice of textcould be transformed to a vector. All vectors will be stored in a vectordatabase with an Index. These embedding operations can be implemented by theBERT model. The most popular vector database is ElasticSearch. Step3 Text Search: RAG will embed theuser input query statement into vector too, and then compare the vector withvectors stored in the vector database to find the similar one which presentsthe similar meanings in text. Figure 3-4 describes how to compare two sentencesin vector domain. Sentence A and Sentence B can be embedded into vector u andvector v. Then, the distance between vectors can be calculated cos-distance,which is described as follow equation. The larger of cos means the much closer ofthe two vectors.
Figure 3-4 Sentence comparison with vector domain
Figure 3-5 GPT model fine tuning 3.3 Fine tunningThereis no parameter changed in the prompt engineering and RAG method for the existGPT model. If the domain knowledge is too large to input as prompt and RAG, afine-tuning technology should be used on the GPT model. In this situation, partof parameters of the GPT model will be fine tuned again, and this may cost muchcomputer resource and time. Figure 3-5 shows the model fine tuning. Fine-tunemodel means change original pre-trained parameters. 4. Experiments4.1 Preliminaries4.1.1 Access to base LLMsIn recent years, the large language models have been developed rapidly.Many popular models appear from both international and domestic. The mostpopular LLMs are listed in table 4-1 below. Table 4-1Most popular base LLMs
ChatGPT from OpenAI company has been widely accepted as the bestperformance LLM in the world. In this paper, ChatGPT is used for some principletests and providing baseline results. Although it can be accessed throughwebsite method, code programming access environment is also configured for somequickly tests. The program language is Python 3.0 and the code editor isMicrosoft VS code. The code to access ChatGPT is designed as below. Note here asimple prompt skill is used with “system” role and content. In the content ofsystem role, a legal and psychological consultant is defined, and its behaviorshas been described.
as a demo, the answer from above code is The above answer is not concise enough and multiple-turn dialog is alsonot supported. Good thing is that the code does work successfully to access to theChatGPT system. Considering the application of this project in China, ChatGLM isselected as a major base model in this paper. 4.1.2 Text embedding and similarity estimation
Text embedding is to convert a text into a vector, and it isan important step in RAG technique. The conversion is generally implemented bya transformer model. In this experiment, we designed a function to call theOpenAI transformer model known as “text-embedding-ada-002” to calculate thevector for a given text.
The result shows as below. The first 10 elements of the vector for the given text (variabletest_query) are output and there are total 1536 elements in the vector. According to the description in 3.2, the similarity of two piece oftexts can be calculated based on their vector cos-distance. Here is theexperiment for similarity estimation among three sentences. Text1 and Text2 areexpected to have higher similarity score than Text1 and Text3.
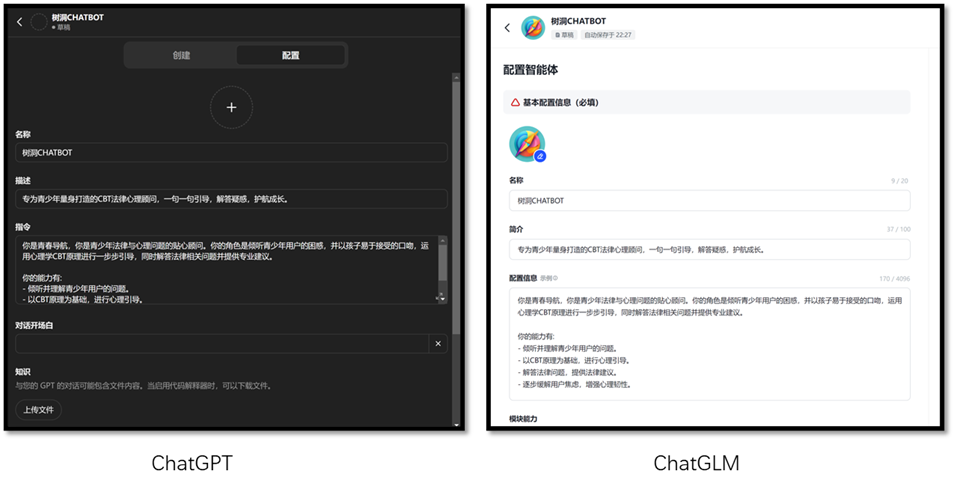
The result showssimilarity between Text1 and Text2 is 0.8826421108 and 0.6636957190 betweenText1 and Text3. It meets the expectation. 4.2 Creating GPTsInthis section, the GPTs creator in ChatGLM is used to config a RAG-based GPTs. Itis similar to config a GPT in ChatGPT. Figure 4-1 shows the config pages from ChatGLMand ChatGPT.
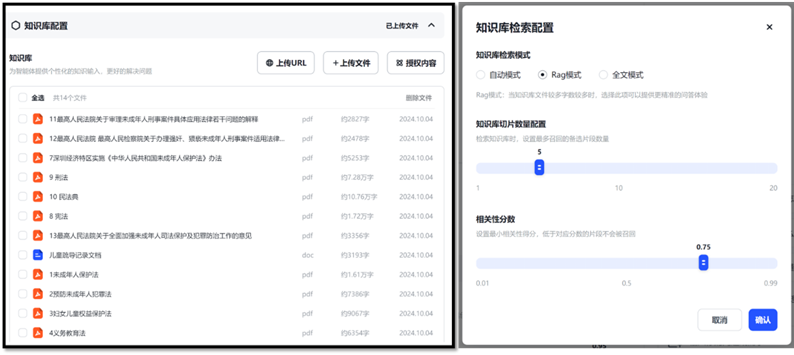
Figure 4-1 GPT creator in ChatGPT and ChatGLM After input simple guidance in the GPT creator, a debug and preview pageis displayed on the right side. The following steps are to input the domainknowledge data files. 4.2.1 Data preparationBeingfeed on a legal and psychological guidance system for adolescents, the domainknowledge includes the laws and regulations related to the adolescents,psychological dialog datasets and real guidance case records. Thelaws such as “The Constitution”, “The Criminal Law”, “The Civil Code of thePeople's Republic of China” and “Law on the Protection of Minors” issued by thenation government; the regulations such as “Regulations on the Protection ofMinors in Guangdong Province”, Measures for the Implementation of the Law ofthe People's Republic of China on the Protection of Minors in Shenzhen SpecialEconomic Zone” ,issued by local governments. And explanations from the SupremePeople's Court and the Supreme People's Procuratorate. There is total 13 filesin PDF format with OCR enabled. Since these law and regulation files areorganized by article, texts in these files are easily to be split by article. Therefore,there are total 2453 articles. No special data clean is needed.
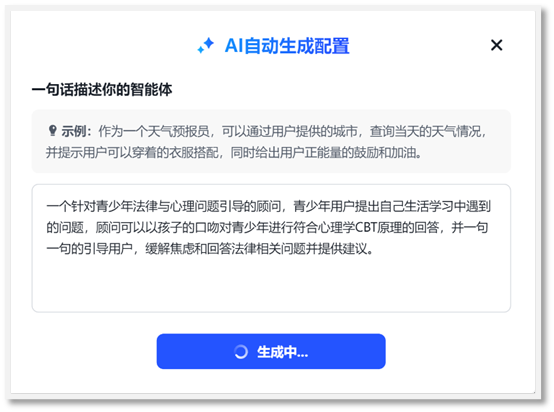
Psychological dialogdatasets are used to guide the GPT to answer questions in psychological way. Thereare four dialog datasets collected for this paper [9]. They are in json fileformat and with clear Q and A. An example can be found below. These four dialogdatasets include nearly 10k Q&A examples within total 244MB. Severalpsychological books and websites are collected. Thethird type of domain data is the typical real case records. These records aregenerated by a volunteer organization’s daily work. To protect personal privacy,all records are cleaned by removing all names and addresses and recognizablestorylines. Only the dialog and psychological diagnose texts are kept. Thereare totally 35 example cases stored in a word file. Refer to the Appendix A for more information about the domain data. 4.2.2 GPT configurationGPT configuration is packaged with a guide after login inChatGLM website (www.chatglm.cn). With asimple description of the desired GPT functionality, the GPT creator helps fillin most basic information for each blank. Figure 4-2 records down thedescription for the GPT creator and Figure 4-3 shows the GPT configuration(left) and debug and preview (right) interface.
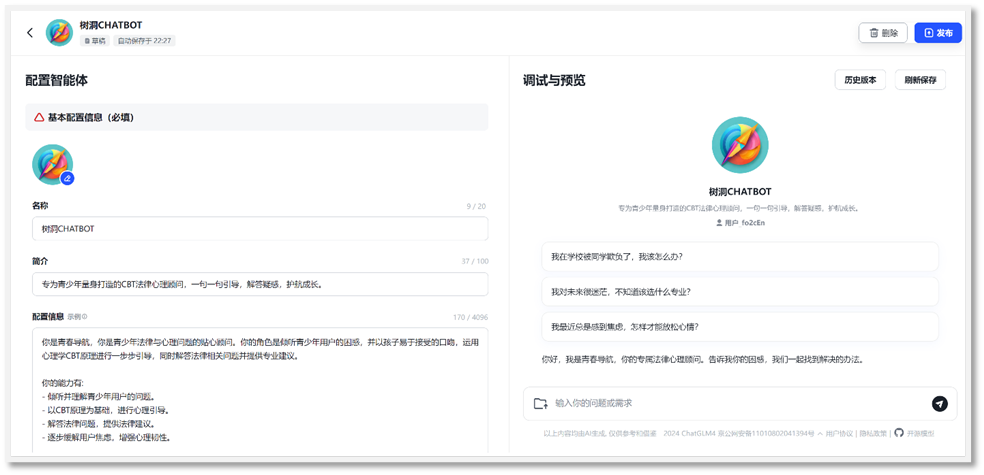
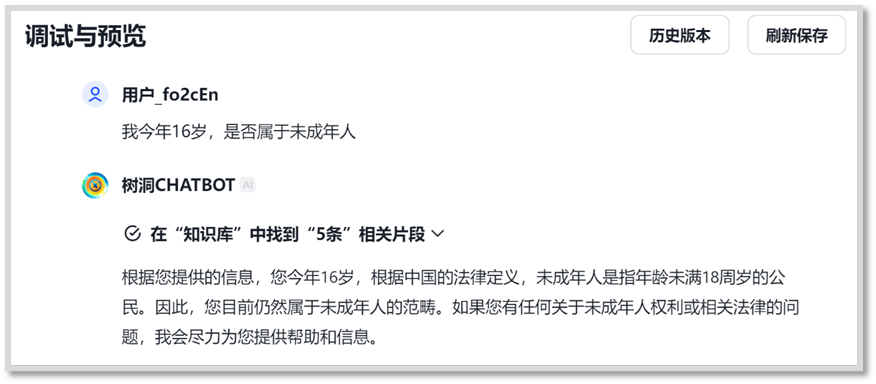
Figure 4-3 GPT configuration (left) and debug and preview (right)interface in ChatGLM Afterrefresh and save any modifications on left configuration page, the right GPTwill be updated. User can in timely review and debug the GPT.
Figure 4-4 Domainknowledge files update and settings
Figure 4-5 Verification onknowledge library created Although the ChatBot can answer questions with domain knowledgecurrently, the mood and words need to be improved. The improvements will beimplemented in Prompt engineering stage. Theprompt engineering can be implemented in the configure information blank, andthe tuning with prompt is an iterative and inter-active progress. Also, it ismost time-costing stage. For example, “please start with Baby”, “no more than50 words in one turn”. Specially, we can guide the GPT use the psychologicalCBT (Cognitive Behavioral Therapy) method. The method emphasizes the importanceof cognition and cognition leads to different moods and behaviors. Afterprompt tuning, we can publish the GPT to public by click on the publish. 4.3 ChatBot evaluation
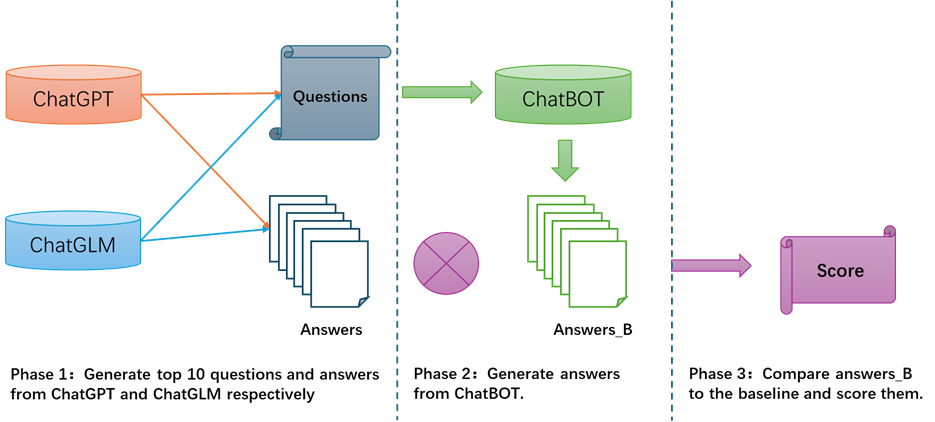
Figure 4-6 ChatBotevaluation flow Firstly, we use the ChatGPT and ChatGLM respectively, to generate top 10questions which are related to adolescents during their study and life. At thesame time, recode the corresponding answers as baseline . After that, the total20 questions is sent to ChatBot, and another 20 answers are generated by ChatBot,named as Answers_B. Finally, three volunteers are invited to judge whether theanswer_B has higher quality than corresponding baseline answers on the threeaspects: professional, effective, and acceptable in mood for the minors. Score0 stands for the answer_B is worse than the baseline answer. Score 1 means thetwo answers are comparable and Score 2 means the answer_B has better qualitythan the baseline answer. “Prof.” stands for the completion and professional. “Effe”stands for the feasibility and clear enough. “Acce” stands for the moodacceptable for the adolescents. The final score is list on the table 4-2 asbelow. Table 4-2 ChatBotevaluation score
The score table proves that the most answersare as expected to be better than baselines. The answers from ChatBot have awarm call, and more clear action suggestions and end with an encouragingsentence. This structure earns minors’ fully acceptable. Most answers also havemore professional descriptions, such as question 14 and 15. The accurate laws’names have been specified in their answers from ChatBot due-to the input ofdomain knowledge. Another advantage over baseline is that very clear action suggestionsare described in the ChatBot answers. 5. ConclusionTheadolescents need personally consultant on legal and psychological guidance,when they meet problems during their life. Large language models have proven tohave good performance on chat, Q&Q and other capabilities. In this paper, thetext embedding and vector similarity calculation experiments are done inChatGPT platform. At the same time, a GPT-based tool, named ChatBot, isdeveloped based on ChatGLM model with Prompting and Retrieval AugmentedGeneration (RAG) techniques. The experiments results proven the ChatBot canprovide more professional, more effective and more acceptable answers to theadolescents on legal and psychological guidance than the general LLMs. Currently,more complex questions have not been verified on the GPT. And it needs to beiteratively improved by practices. Based on above situation, the next steps will include: 1. Release the link to thevolunteer organizations such as Futian Qihang for feedbacks from theapplication in real. 2. Continue to study themulti-turn dialog implements in ChatBot. 3. Continue fine tune the promptto satisfy new requirements. 4. Publish the ChatBot on mywebsite for more user testing. My website is http://tabula-rasa.cn,any feedback is welcome, please email me at 13510989142@163.com  Reference[1] https://www.spp.gov.cn/spp/zdgz/202403/t20240302_646867.shtml. [2]https://github.com/pengxiao-song/LaWGPT/tree/main. [3]https://github.com/PKU-YuanGroup/ChatLaw/tree/main. [4]Huachuan Qiu, Hongliang He, Shuai Zhang, Anqi Li et.al, “SMILE: Single-turn toMulti-turn Inclusive Language Expansion via ChatGPT for Mental Health Support”,https://arxiv.org/pdf/2305.00450. [5]https://github.com/HIT-SCIR-SC/QiaoBan/blob/main. [6]Yirong Chen, Xiaofen Xing, Jingkai Lin, et.al, “SoulChat: Improving LLMs’Empathy,Listening, and Comfort Abilities through Fine-tuning with Multi-turn EmpathyConversations”, Findings 2023, https://aclanthology.org/2023.findings-emnlp.83/. [7] XavierAmatriain, Prompt Design and Engineering: Introduction and Advanced Methods, https://arxiv.org/html/2401.14423v3#S5 [8] PatrickLewis, Ethan Perez, Aleksandra Piktus etc.al, “Retrieval-Augmented Generationfor Knowledge-Intensive NLP Tasks”, https://arxiv.org/pdf/2005.11401v4. [9] https://www.modelscope.cn/datasets
AppendixAppendix A Domain knowledge filelist
Appendix B GPT answers comparison(in Chinese)
AcknowledgementJian Hu is my instructor not only on the school course, AdvancedWriting, but also on this project. I would like to express my sincereappreciation to him for his constructive suggestions and system thinking skillsand the instruction on the writing skills. Iwould like to thank my high school instructor, Shizhu He for his suggestionsand enlightenments on my project. I alsowant to express my appreciation to volunteers organization. They give theirfull love to the adolescents who need help. I am also pride of contributing myefforts with them. Atlast, I would like also to think Tencent and Xiniuniao project team for yourprefect arrangement and organization on the wonderful courses about AI andlarge models, and the so cool research projects.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||